
AiSK

2025-03-27
過去幾年, AI 應用一直在讓我們大開眼界,而且還沒有停下的跡象。從大型語言模型( LLMs )如 GPT-3 和 GPT-3.5 ( ChatGPT )開始, LLMs 已經被應用到各種領域,並且逐漸結合了更多種類的資料像影像、影片、聲音與語音。這些進展帶動了多模態 AI 的崛起以及相關應用的誕生。
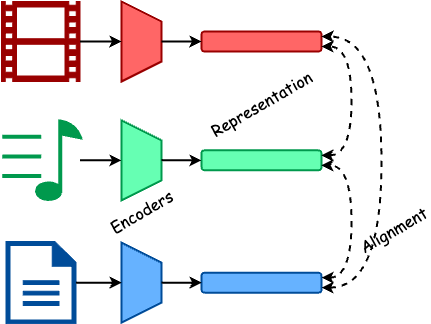
多模態 AI 指的就是能同時理解並產出多種模態(形式)資料的模型,自然會比只處理單一模態(single-modal, or unimodal)的 AI 更強大。這裡的「模態」(modality)指的是資訊呈現的形式,如文字是一連串的詞彙,而影像是像素的二維陣列。人類能夠透過視覺、聽覺、觸覺等多種感官來感知世界,並綜合這些感官資訊在腦中做出判斷或行動。多模態 AI 如人腦般,會先透過編碼器模型(encoder models)將不同模態的資料轉換並對齊到一個共同的表示,也就是特徵(features),這通常是一個數值向量,以便電腦能夠後續處理。之後,模型會透過一個統一的生成模型(generator model)以及解碼器模型(decoder models)來將這些表示轉換成它的輸出。
在本篇文章,我們會先回顧兩個多模態 AI 模型——視覺語言模型和音訊語言模型——中,一些熱門或新興的應用,並介紹了它們如何在工作或日常生活中協助我們。接著,我們會探討這些應用當前所面臨的挑戰,最後再對多模態 AI 的未來方向進行總結與展望。

視覺語言模型( Vision-Language Models,VLMs )常被用於各種內容創作。自 2020 年起,文字轉圖片(text-to-image)生成已成為一種熱門應用。 AI 助手可以依照使用者的文字提示(prompt)生成圖片,讓你藉由一系列圖像來說故事。而現在更進一步,文字轉影片(text-to-video)也已經成形,原理類似文字轉圖像,但它會把影片切成許多連續的畫面區塊(patches),根據時間與位置來排序,並把文字特徵與對應的視覺特徵互相對應。如此一來, AI 就能理解一個詞在時間序列中哪時該出現,也知道該如何在影片中呈現。
另一個流行的應用是 Avatar ,它跟文字轉影片類似,能根據你的文字稿或音訊,生成一個模擬人形角色,並包含臉部表情與動作。 Avatar 模型會比對原始範本(例如一位真人演員)的臉部和身體特徵進行訓練。這在新聞播報、線上教學和遊戲開發裡都相當有幫助。

VLMs 也被用在影像內容理解與分析任務上。早期的電腦視覺模型常聚焦在單一任務,如物件偵測或臉部辨識。但若加上 LLMs 的幫助,整個模型就能「懂」語言,處理的任務範圍也更廣。視覺定位(visual grounding)與推理(reasoning)可以分析圖片或影片裡的事件,並對應到文字。現在,你可以要求 AI 幫你在照片裡找出貓咪,或替你整理旅途中拍下的所有照片。
自動語音辨識(Automatic Speech Recognition,ASR ),也稱為語音轉文字(Speech-to-text,STT),比現代 LLMs 更早開始發展,因為智慧手機、 IoT 智慧家居、機器人等對語音助手的需求很高。隨著現代 LLMs 架構的出現,音訊語言模型的效能也有了大幅提升。
內容創作者(如影片製作者或 podcaster)可能在影片或音訊中錄製了自己的聲音,接著語音合成(speech synthesis)工具將其語音翻譯成不同語言,讓世界各地的觀眾都能收聽。
文字轉語音(Text-to-speech,TTS)是語音合成工具的常見功能。它可以把文字直接轉成語音,被廣泛用於有聲書、語音助手或語音訊息等場合。
而文字轉音樂(text-to-music)則是音訊-語言模型裡另一个熱門應用。它與 TTS 模型結構相似,但主要目標是生成音樂特徵(如節奏、曲風、樂器等),而不是將文字內容轉成發音。有了這項功能,你甚至不需要任何作曲基礎,就能憑藉文字描述來生成並自訂音樂。
儘管多模態 AI 已經取得重大進展,但因為涉及更複雜的資料與任務,它現在面臨的風險與挑戰也比以往更多。
在網路服務和軟體開發中,安全性永遠擺在第一位, AI 也不例外。易用性和便利性往往是安全性的最大敵人。當你使用 AI 助手時,通常會被要求授權存取你的資料,例如照片、影片和語音錄音。一旦授權,這個 AI 就成為你的資料代理,因此,保護 AI 助手的重要性不亞於保護你的個人資料。

另一種資料外洩風險則在模型本身。更明確地說,是被訓練或 fine-tuning 的模型參數裡。許多應用都提供個人化或客製化功能,如果這種功能是透過 fine-tuning 達成的,那麼你的資料等於已被該模型「看過」或「聽過」。由於模型無法輕易辨別提示詞(prompt)中哪些部分是敏感資訊、哪些部分不是——因為這些資訊已經轉為人類無法理解的數值,並在「黑箱」中處理——因此很難保證資料不被誤用。舉例來說,「幫我找兩個月前和某人見面的影片」,如果你是在出差可能不敏感,但如果你是在秘密約會,肯定不希望被任何人看見。
為了防止不當應用,開發者通常會透過 prompt engineering 的技術,設定「系統提示詞」(system prompts)規則來限制 AI 的用途,比如 AI 聊天機器人只能提供客服服務或只回答特定問題。 Prompt hacking 則是用戶端反過來做 prompt engineering,企圖繞過系統提示。如果系統提示詞設計不夠完善,駭客可能藉由使用者提示詞(user prompts)讓 AI 忽視系統提示詞。更糟的是,如果系統提示詞中包含商業機密或敏感資訊,駭客便能利用此手法取得。在多模態 AI 中, prompt hacking 更難被偵測,因為提示詞不僅限於文字,也可能包含影像、影片以及聲音。
隨著 AI 的功能越來越強大,也更容易出現不適宜或惡意的內容,例如暴力、色情與仇恨言論。這些內容可能是 AI 意外生成的,或是惡意用戶故意生成的。為了避免此情況,開發者使用一種稱做內容過濾器(content filters)的後處理程序,包含一些手動設定的規則或簡化模型。若偵測到不當資訊就會停止生成或拒絕顯示,也可能同樣套用在使用者的輸入(例如提示詞與影像)上。然而,內容過濾器也並不完美:它可能誤判正常內容為有害內容(誤報),或者讓有害內容通過(漏判)。舉例來說,如果你在電影業工作, AI 難免需要處理帶有暴力或性暗示的場景,你可不希望 AI 毫無預警就停止工作。
語境(context)指對話中的背景資訊,包括對話紀錄、用戶檔案、時間、地點,甚至天氣都是其一部分。在 LLMs 中,語境會以一串文字詞元(tokens)形式,與提示一同送入模型。在多模態 AI 中,語境還可以是影像、影片或音訊,這些資料所含有的資訊更豐富,能轉換成的詞元量也大很多。詞元越多,複雜度越高,所需的時間與成本也越大。把所有語境資訊都放進 AI 中是不可能也不實際的,因此,如何選擇最重要的語境資訊就尤為關鍵。檢索式輔助生成(Retrieval augmented generation,RAG)技術便是先檢索出最相關的內容,再根據這些內容進行生成,以兼顧效率與準確度。
上述長語境的問題是效率,而缺失或少量語境則會影響準確度,還可能引發公平性及倫理問題。由於模型是為了追求高準確度而在龐大的資料集上訓練,因此往往偏向多數情境,但對於少數情境未必合適。因此,模型所學到的「常識」並不一定適用於世界上所有用戶。對任何提供全球服務的 AI 來說,要滿足來自不同地區、文化與語言的用戶是至關重要的。有些應用會針對不同族群使用較小但更專門的資料集進行 fine-tuning ,通常能得到更好的效果,但也會造成不同群體間的知識落差,因為不同版本的模型彼此間無法共享知識。
多模態 AI 的未來主要會往三個方向發展:優化、客製化與整合。
「優化」不僅意味著讓模型更快、更準,也包括改進輸出結果的傳輸方式。相較於純文字的 LLMs,多模態 AI 可以輸出各種型態的資料,例如文字轉影片(text-to-video)生成或 Avatar 服務的原始輸出,通常是一連串圖像,若要透過網際網路傳送給終端用戶,其成本相當高。為了讓輸出能被串流(streamable),有些人會在後處理階段將輸出編碼成影片格式(例如 MP4)。也有研究人員嘗試開發讓多模態內容能夠即時產出、且是可串流傳遞的格式,既能提升使用者體驗,也能降低成本。
「客製化」則針對特定客戶或目標族群提供專屬且客製化的服務,透過 fine-tuning 模型或預先設定的商業邏輯,提升輸出的品質與效能。先前提到的那些風險和挑戰也可以透過客製化來解決。一般而言,這是一種控制輸出結果的方式,讓用戶能得到更符合他們需求的精準結果。比如,提示反轉(prompt inversion)就是一種輕量的模型技術,讓用戶能在文字轉影片時,客製化自己的素材或臉孔,讓 AI 生成含有這些元素的影片。
「整合」指的是將多個模型合而為一個服務,或擴充模型可處理的輸入與輸出模態,後者比前者更困難。舉例來說,一個文字轉影片生成器(tex-to-video generator)可以與文字轉音樂生成器(text-to-music generator)結合,讓用戶能在同一平台上同時生成影片與背景音樂。更進一步,如果模型能夠理解文字、影片與音樂之間的關係,就能自動生成一段與影片內容相配的背景音樂。同樣地,如果 Avatar 與語音合成(speech synthesis)整合,使用者只需選擇一種視覺風格與一種語音風格,再輸入逐字稿, AI 就能一鍵生成全部內容。這種整合雖然功能更強大,但開發難度也更高。

LLMs 的變化速度之快,讓今天所見的多模態 AI 應用在過去幾乎難以想像。許多公司與它們的 AI 工程師正致力於為世界帶來各種 AI 服務。即便在這篇文章撰寫的同時,仍有源源不絕的新應用正在開發,讓人們在工作與日常生活都能享受到這些技術帶來的便利。

填寫右邊的表格,讓顧問幫助您制定成功的影音策略

在市場快速變動、技術持續革新的今天,企業若想穩健前行,光有經驗已經並不足夠。員工是否具備持續學習與成長的能力,正是企業保持競爭力的關鍵。不論是推動數位轉型、優化內部流程,還是因應業務擴張,人才的培養都會直接影響組織的靈活度與執行力。因此,教育訓練不只是入職流程的一部分,更應被視為企業長期發展的重要策略。

掌握 OBS 直播技巧,從入門到進階,打造專業直播內容!本指南涵蓋 OBS 安裝、設定、串流等步驟,並提供進階技巧,幫助您提升直播品質。立即開始您的 OBS 直播之旅!