

Beyond Large Language Models: Multimodal AI Applications Will Be Everywhere
2025-03-27
Applications of AI have amazed us for the past few years, and it doesn't seem to stop. Starting from large language models (LLMs) like GPT-3 and GPT-3.5 (ChatGPT), LLMs have been applied in various fields and were connected to many more kinds of data like images, videos, sounds, and speech. There we saw the rise of multimodal AI and their applications.
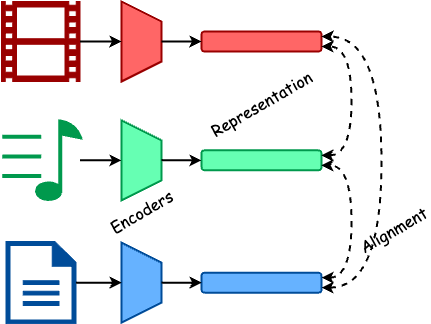
A multimodal AI is a model that is able to understand and generate multiple modalities, and it is thus more powerful than a single-modal, or unimodal, AI. The term modality refers to the way information is presented. For example, a text is a sequence of words, while an image is a 2D grid of pixels. Human beings perceive the world through multiple senses, such as vision, hearing, and touch. We process all kinds of information in our brains together, and then perform actions or make our decisions. Like human brains, the very first task of a multimodal AI is using encoder models to convert and align different modalities into a common representation, a.k.a. features, which is usually a numerical vector, so that computers are able to process them. Afterwards, the action of the model is using a unified generator model and decoder models to transform these representations into its output.
In this article, we first looked back at some popular or rising applications in 2 cross-modal AI models: vision-language models and audio-language models. We introduced what these models help people in their work or daily life. We then pointed out some of the challenges of these applications. At last, we concluded and discussed the future of multimodal AI.
Applications of Multimodal AI
1. Vision-Language Models

1-1. Content Generation
A common use of vision-language models (VLM) is content generation. Text-to-image generation has become a popular application since 2020. An AI assistant generates images from your text prompt, so you can use it to create your own story from a sequence of images. These AI are now equipped with an even stronger feature: text-to-video generation. It uses the same mechanism as text-to-image generation. By splitting a video into a sequence of patches ordered by time and position, the model learns to correlate each text feature to all of its corresponding visual features. The AI thus knows how a word would present in temporal order and how it looks like in a video.
1-2. Avatar
Avatar is another popular application. Similar to text-to-video generation, Avatar services generate a simulated human with facial expressions and body movements, based on the input transcript or audio recording. An avatar model is trained by matching the visual features of the face and body of the template. This is useful in news broadcasting, online teaching, and game development.

1-3. Content Understanding and Analytics Tasks
VLMs are used in visual content understanding and analytical tasks as well. Traditional computer vision models only focus on a very specific task, such as object detection or face recognition. With the help of LLMs, traditional models are now language-aware, and can do many more general tasks. Visual grounding and reasoning analyzes the events in your pictures or videos, and binds them with languages. Now you can ask your AI assistant to find your cat in a picture, or summarize your photos taken during a journey.
2. Audio-Language Models
2-1. Automatic Speech Recognition or Speech-to-text
Automatic speech recognition (ASR), or speech-to-text (STT), models have been developed much earlier than modern LLMs, since the demand for voice assistants in smartphones, IoT smart home devices, and robots is high. With the architecture of modern LLMs, the performance of audio-language models has been improved significantly.
2-2. Speech Synthesis
Content providers, such as video creators or podcasters, may have their speech recorded in a video or audio. Speech synthesis tools are used to translate their speech into different languages, so they can reach more audiences in the world.
2-3. Text-to-speech
Text-to-speech (TTS) are also a common feature in speech synthesis tools. It is now widely used in converting textual contents to audio, such as audiobooks, voice assistants, and voice messages.
Text-to-music generation is another popular application of audio-language models. It shares basically the same model architecture as TTS models, but it focuses on creating musical features, e.g. tempo, genre, instruments, etc., rather than the pronunciation of the text input. You are able to generate and customize your music from text descriptions only, without the knowledge of music composition.
Risks and Challenges of Multimodal AI
Despite the great progress in multimodal AI, it now faces even more risks and challenges than before, as it is now dealing with more complex data and tasks.
Security and Privacy
Security must always be the first concern in web services and software engineering. The same applies to AI. Easiness of use and convenience are the biggest enemy against security. When you use an AI assistant, you are often asked to grant permissions to access your data, such as your photos, videos, and voice recordings. From then on, this AI becomes your proxy to your data, so protecting your AI assistant is as important as protecting your data.

Another data leakage happens in the model itself, to be more specific, the model parameters being trained or fine-tuned using your data. Many applications serve personalized and customized features. If this feature is provided by a fine-tuning process, then your data has been "watched" or "listened" by the model. It is difficult to let the model determine which part of your prompt is sensitive and which part is not, since this information is now represented in non-readable numbers and processed in a black box. For example, "help me find the video of me meeting with someone 2 months ago" may not be sensitive if you were on a business trip, but you won't want anyone to see it if you were on a secret date.
To avoid misuse, AI chatbots are often designed to provide only a specific function, such as customer service or question answering about a specific topic. Developers set these rules as "system prompts" via the technique called prompt engineering, which is to design the rules of user prompts, so that AI will refuse to do something that is not allowed. Prompt hacking is the client-side prompt engineering to bypass system prompts. If the system prompt is not well-designed, it may be ignored by the cracker's user prompt. Even worse, if the system prompt contains business secrets or sensitive information, crackers can use it to get the information. In multimodal AI, prompt hacking is more difficult to detect, since the prompt is not only text, but also images, videos, and sounds.
Content Safety
While modern AI applications become more powerful, they have the ability to generate harmful content, too. These contents may be generated accidentally by AI, or may be generated on purpose by malicious users. Violence, sex, and hate speech are typical elements of unsafe content. To prevent this, developers use content filters, which are usually a post-process including some hand-crafted rules and/or a light-weight model. If the content filter detects something inappropriate, the AI assistant will probably stop generating or refuse to show it. It may also apply to the user input, such as prompt and images. However, the content filter is not perfect. It may mistakenly treat a normal content as harmful (false positive), or it may let harmful content pass through (false negative). For example, if you're in a film industry, you may have your AI to deal with some violent or sexual scenes, and you don't want your AI to stop working because of these scenes.
Interaction with Context
Context is the background information during a conversation. Dialogue history, user profile, time, place, and even weather are all parts of context. In LLMs, context is a sequence of language tokens that are sent to the model along with the prompt. In multimodal AI, context can be images, videos, or audio. These kinds of data have richer information than text, and are represented in much more number of tokens. More tokens results in more complexity, more time, and more cost. It is impossible and impractical to put all context information to your AI. Therefore, to determine which part of the context matters is an important task across multiple modalities. Retrieval augmented generation (RAG) is a technique to trade accuracy for efficiency. It first retrieves the most relevant information and then generates the output based on the retrieved information.
Long context, as described above, is an issue of efficiency, while missing or minor context is an issue of accuracy. This is related to fairness and ethics as well. The model was biased to the majority because it was trained on a very large dataset for accuracy, but minor cases are not representative. As a result, the "common senses" learned by the model may not suit all users in the world. For any global AI service, it is crucial to serve users from different regions, cultures, and languages. Some applications provide fine-tuned models for different groups of people, using a smaller but more dedicated dataset. This usually results in a better performance, but it also causes a knowledge gap between different groups, as one model has no knowledge of the others.
The Future of Multimodal AI
The next step of multimodal AI contains 3 directions: optimization, customization, and integration.
Optimization
Optimization not only means to make the model faster and more accurate, but also to improve the deliveries of the output content. The output of an LLM is text-only, but multimodal AI can output various kinds of data, and some of them are difficult to transmit. For instance, the raw output of a text-to-video generator or an avatar service is most likely a sequence of images, which costs a lot to deliver to the end user through the internet. To make the output streamable, some employ a post-process to encode the output into a video format, say MP4. Some researchers have been working on generating any multimodal contents in a real-time, streamable format. This will eventually bring better user experience and lower cost.
Customization
Customization, on the other hand, focuses on providing a dedicated and customized service to a specific customer or a target group. It aims to provide a better quality and performance of its output, via a fine-tuned model or a pre-defined business logic. The challenges introduced above can be resolved by customization, too. Generally speaking, it is a way of controlling the output, so that users can get more accurate results that suit their needs. For example, prompt inversion is a light-weight technique for users to customize their own materials, or even their own faces, to a text-to-video generator, and the AI can generate a video containing these materials.
Integration
The integration of multimodal AI is to combine multiple models into a single service, or to extend its capability of input and output modalities, which is a harder way than the former. A text-to-video generator may be combined with a text-to-music generator, so a user can generate a video and a background music on the same platform. Furthermore, if the model is aware of the relation between text, video, and music, it can then automatically generate a video with the background music that fits the video content. The same applies to avatar combined with speech synthesis, for example, a user only has to choose a visual style and a voice style, and input the transcript, and then the AI will generate everything via a single click. Integration is more powerful but also more difficult.

The change of LLMs was so fast that it was hard to imagine the multimodal AI applications we have today. Lots of companies and their AI engineers have been working on delivering AI services to the world. Even during the writing of this article, new applications are being developed and are benefiting people in their works and daily lives.
Like This Article?
Stay ahead of the curve—subscribe to our newsletter and get the latest updates, expert insights, and exclusive content delivered straight to your inbox. Whether you're looking for tips, trends, or behind-the-scenes stories, we've got you covered. Don’t miss out—join our growing community today!

LET'S TALK!
Interested in a demo, free trial, or pricing? Fill out the form, and one of our consultants will get in touch to assist you.
Related Articles
What Is a Cutdown Video? When to Use It—and How AI Can Transform the Process
Learn what cutdown videos are, when to use them, and how AI is revolutionizing video repurposing for enterprises. Discover smarter, faster, and scalable solutions with BlendVision.

NAB 2025 Trend Report: How AI is Taking Over Media Workflows
Discover the top AI-powered technologies unveiled at NAB Show 2025. Learn how enterprises are using AI to revolutionize media production, live streaming, and content monetization with scalable SaaS solutions.

Why Multimodal Literacy Is Essential in the Age of AI-Driven Media
A dynamic image showcasing AI, media interaction, and sports entertainment—representing the intersection of technology, storytelling, and multimodal communication in modern media.